


GPT-4爆火,去中心化算力能解决AI算力难题吗?

上周,OpenAI 大型语言模型 GPT-4 一经公布便引发了全球科技圈与媒体的关注,60秒创建出一款小游戏,将一张草图快速变为功能性的网站,完美通过历史、数学等几乎所有的学科考试,检查代码漏洞等等,各种逆天的功能展示它极为强大的能力,可以说,GPT-4 成为了在知识、技能、逻辑领域的全能人才,比以往的任何 AI 都要强大,而这一款疯狂的产品或将预示着 AI 奇点的到来。
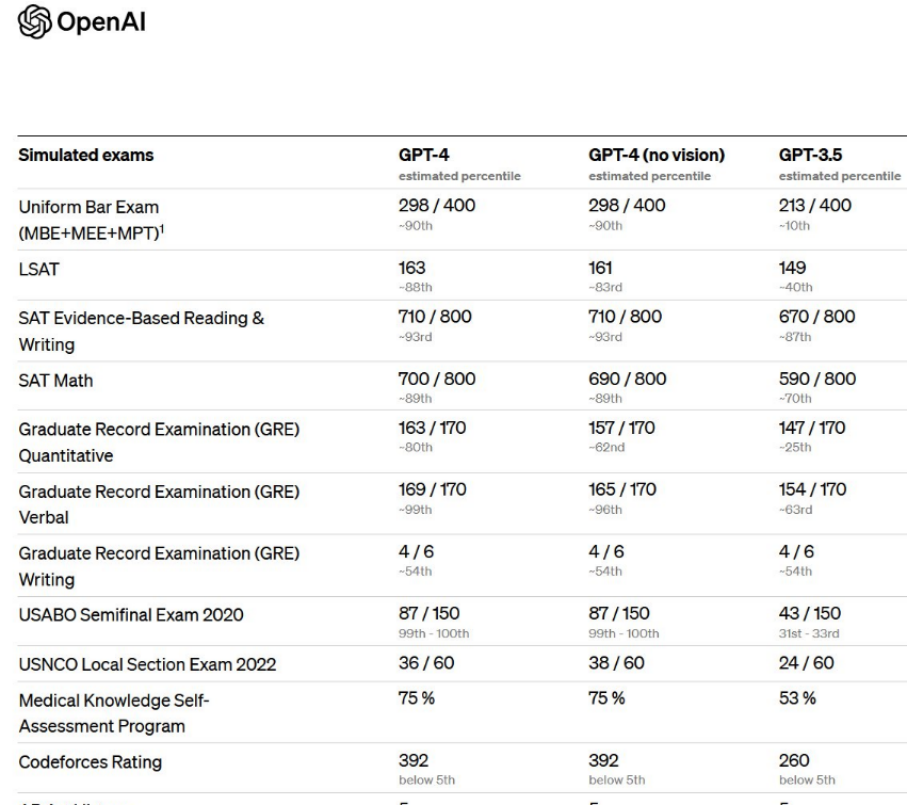
GPT-4与GPT-3.5各项考试成绩对比
在 AI 开始不断刷新人们认知的同时,另一个更为底层的领域也同样发生着巨变,那就是算力。众所周知,AI 模型都需要消化大规模的数据,同时也需要消耗更为庞大的算力,诸如图像识别、自然语言处理和机器学习等各种AI应用和模型的训练,都依赖于庞大算力的加持。
据 OpenAl 此前发布的数据显示,从2012年到2020年,其算力消耗平均每3.4个月就翻倍一次,8年间算力增长了三十万倍,更不用谈自去年 ChatGPT 推出后爆火所带来的需求暴涨。
此外,AI 时代算力的增长也远远超过了摩尔定律每18个月翻番的速率,根据中国信息通信研究院的估算,2021年全球超算算力规模大约为14EFlops,预测到2030年全球超算算力将达到0.2ZFlops,平均年增速超过34%。AI 的奇点的到来也将会成就算力领域的黄金时代,同时,算力的发展好坏也将会影响着其未来的发展,两者彼此成就。

OpenAl算力消耗情况 数据来源:阿里研究院《数实融合的第三次浪潮》
目前,关于 AI 算力的优化技术主要有以下几种:
GPU资源池化:通过虚拟化和远程调用,将GPU从硬件定义转换成软件定义的资源池,实现资源的共享、按需分配、弹性伸缩和统一管理。
计算精度优化:通过混合精度计算,利用不同的浮点数类型在保证模型训练和推理效果的同时,降低数据传输和存储成本。
模型压缩优化:通过参数剪枝、量化等方法,减少模型参数量和计算复杂度,降低模型大小和内存占用。
面对算力需求的增长,短期内可以从软硬件和工程优化等角度解决,但在未来十年,二十年之后呢?当芯片逼近量子极限,当 AI 的进化需要越来越庞大的数据、越来越多的预训练模型参数、越来越高的算法精度时,会带来对算力需求的指数级增长,而且这种增长是长期性的,由此带来的成本问题将会成为一个不可规避的难题。同时这也会让 AI 只有巨头才能入局的游戏,据悉,OpenAI 接受微软投资的很大原因就是为了获得微软云 Azure 的计算支持。
所以,为了能降低成本,并获得更多的算力来支持 AI 项目的进一步发展,很多新兴企只能选择与大型云算力企业合作,作为交换让渡出部分权利,而去中心化的算力系统或许能在一定程度上解决这一问题,并降低 AI 模型训练的门槛。
去中心化算力是指将分散在不同地点、不同设备上的计算资源整合起来,形成一个去中心化的网络。以此,为 AI 应用提供更加灵活、高效、低成本的计算服务,其潜在优势体现以下几个方面:
提供分布式计算能力,支持人工智能模型的训练和运行,使任何人都能运行AI模型,并在来自全球用户的真实链上数据集上进行测试。
去中心化还可以通过创建一个强大的框架来解决隐私问题。
通过提供透明、可验证的计算过程,增强人工智能模型的可信度和可靠性。
通过提供灵活、可扩展的计算资源,支持人工智能模型在各种应用场景下快速部署和运行。
提供去中心化的数据存储和管理方案。
目前,已经有项目在探索以去中心算力+AI的组合,例如:
Gensyn:该协议通过智能合约方式促进机器学习(ML)的任务分配和奖励,来快速实现 AI 模型的学习能力,适用于深度学习计算的L1层,可以在大规模、低成本的网络中实现 ML。
Flux:一个基于区块链技术的去中心化 AI 平台,通过智能合约来规范 AI 任务的发布、执行和验证过程,并使用 Token 作为激励机制。
Golem:一个提供算力市场的点对点去中心化计算网络,支持任何人都可以通过创建共享资源的网络来共享和聚合计算资源。
但去中心化算力网络与 AI 的结合也需要解决验证问题,即如何确保运算结果的正确性和可信性。此外,算力增长所带来的电力消耗也是一个不可忽视的问题,据统计,训练 GPT-3 模型消耗的能源相当于120个美国家庭一年的耗电量,而这只是实际使用模型所消耗的电力的40%左右。
相比算力增长来说,能源电力称不上难题,随着技术的突破,AI 所展现出的潜力将会激发了更多的企业和研究机构投身其中,这些问题可能会被一一解决。而从计算机视觉到自然语言处理,从机器人学到推理、搜索,人工智能所带来的生产力变革正在改变我们当前的工作方式,在技术发展的道路上,科幻照进现实只是时间问题。